Summary

The number one rule for high-quality accessible captioning is readability. After all, if nobody can read your captions, then none of the other rules matter. People put so much effort into adding captions. It’s a shame when they make poor captioning choices that you can’t read them.
The following example shows the problem when captions don’t have a dark background for contrast.

A best practice for captioning live events is to hire an amazing human captioner. A11yNYC has worked with Mirabai Knight from the beginning of doing this Meetup. Mirabai presented on Why Human Captioning? at A11yNYC. She gives details on a lot of the reasons why you can’t rely on automated captions. A lot of the things that Thomas and I talk about in this post illustrate why you can’t rely on an artificial intelligence (AI) solution.
AI Captioning Services Used in the Test Cases
Thomas explains Equal Entry’s captioning project in which we looked at four popular AI captioning services:
The first one is YouTube. When you upload a video to YouTube, you set what language the video is being spoken in. You pick one language, and that will typically create AI-generated captions for the video. You can download those subtitles and work with them. YouTube offers VTT, SRT, and SBV caption file formats.
YouTube does not automatically caption all videos. YouTube provides a list of the reasons a video may not generate automatic captions:
- Still processing complex audio.
- Don’t support video language.
- Video is too long.
- Video contains poor sound quality or YouTube can’t recognize speech.
- Video has long period of silence at the start of the video.
- Video contains multiple speakers overlapping or speaking more than one language.
Another captioning service is Microsoft’s Azure Video Indexer. This is a paid service you can try some of its functionality based on the amount of video content. This model is different from YouTube in that you’re paying for each video you upload.
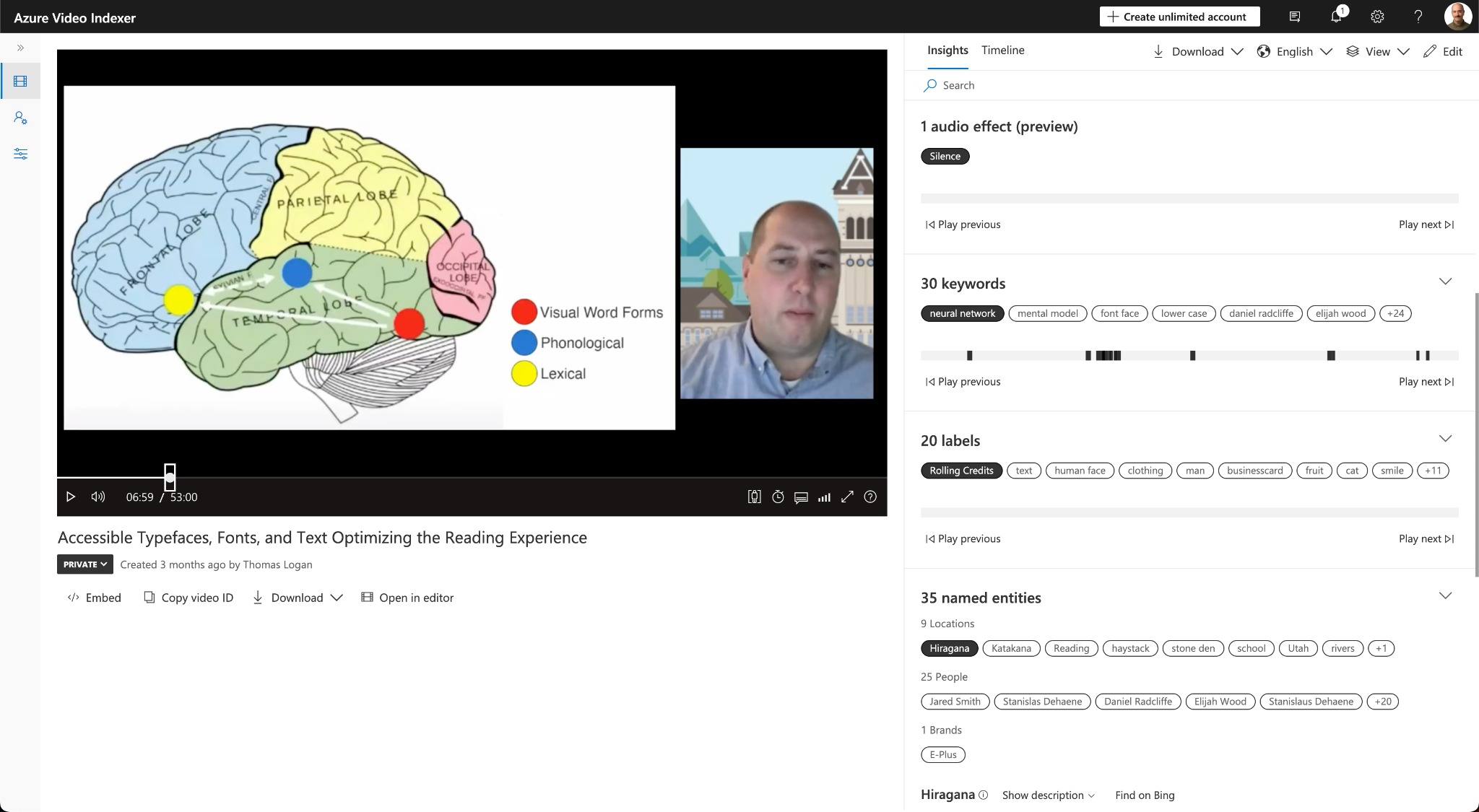
This tool finds keywords, labels, and named entities inside the video. It provides extra logic that goes beyond captions. It’s also trying to do some semantic understanding of the video and provide links. For example, if someone selects a named entity of Elijah Wood or Daniel Radcliffe, the video will jump to where the proper noun was mentioned.
It also offers translations of captions that you can download and work with inside the tool. Another thing that’s interesting in the Azure Video Indexer is the download of the caption VTT file includes a confidence value. This shows the percentage estimate for how accurate or not the caption is.
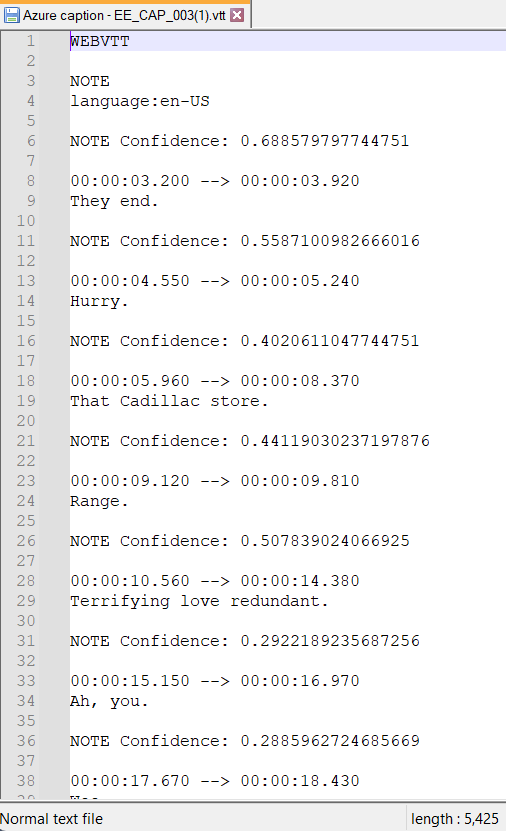
If something has a 40% confidence versus a 29% confidence, the lower the confidence, the more likely it’s incorrect. This API displays this statistic on each line of captions. We didn’t do explorations here, but it’s a good area to explore. People who want to improve AI systems can use these confidence values. People can focus on the lower confidence values and check the accuracy.
The next platform is Vimeo, which uses Google engines for AI captions. Paid Vimeo account holders can download the AI captions.
Last but not least is Whisper. It uses OpenAI, a system that everyone is talking about because it’s behind ChatGPT and DALL-E. Whisper is OpenAI’s automated captioning service. What’s interesting about this technology is it has different models for translation.
They have this idea that they’d ask how many voices the video will need to compare against. The more computation time you spend, the more accurate the translation will be. This lets you choose how accurate you want the AI captions based on what you’re willing to pay. If select a large model, it’ll be more accurate than the small model.
Test Cases for Captioning
Our Equal Entry team is passionate about finding ways to make captions better. We’re fortunate that the team consists of people from all over the world including the U.S., Japan, Brazil, the Philippines, and India. Automatic captions are notorious for being more accurate with English with a plain American accent. Someone whose first language is English but has a British or Australian accent is less likely to be as accurate as someone with an American English accent.
Everyone on the team speaks English. Some as a first or only language while it’s a second language for others. Then, there’s me. I was born in the U.S. and my first language is English. But I have an accent that comes with being born profoundly deaf. All the captioning AIs agree on one thing, they don’t do well with my accent.
Thomas and I want to thank Kevin Vaghasiya for his work in setting up the research and automating the processes for our test cases. Our team made a Google Sheet consisting of the different test cases. We compared them using AI from Vimeo, Azure, YouTube, and Whisper. The spreadsheet shows some statistics to measure how well the service is captioned or not.
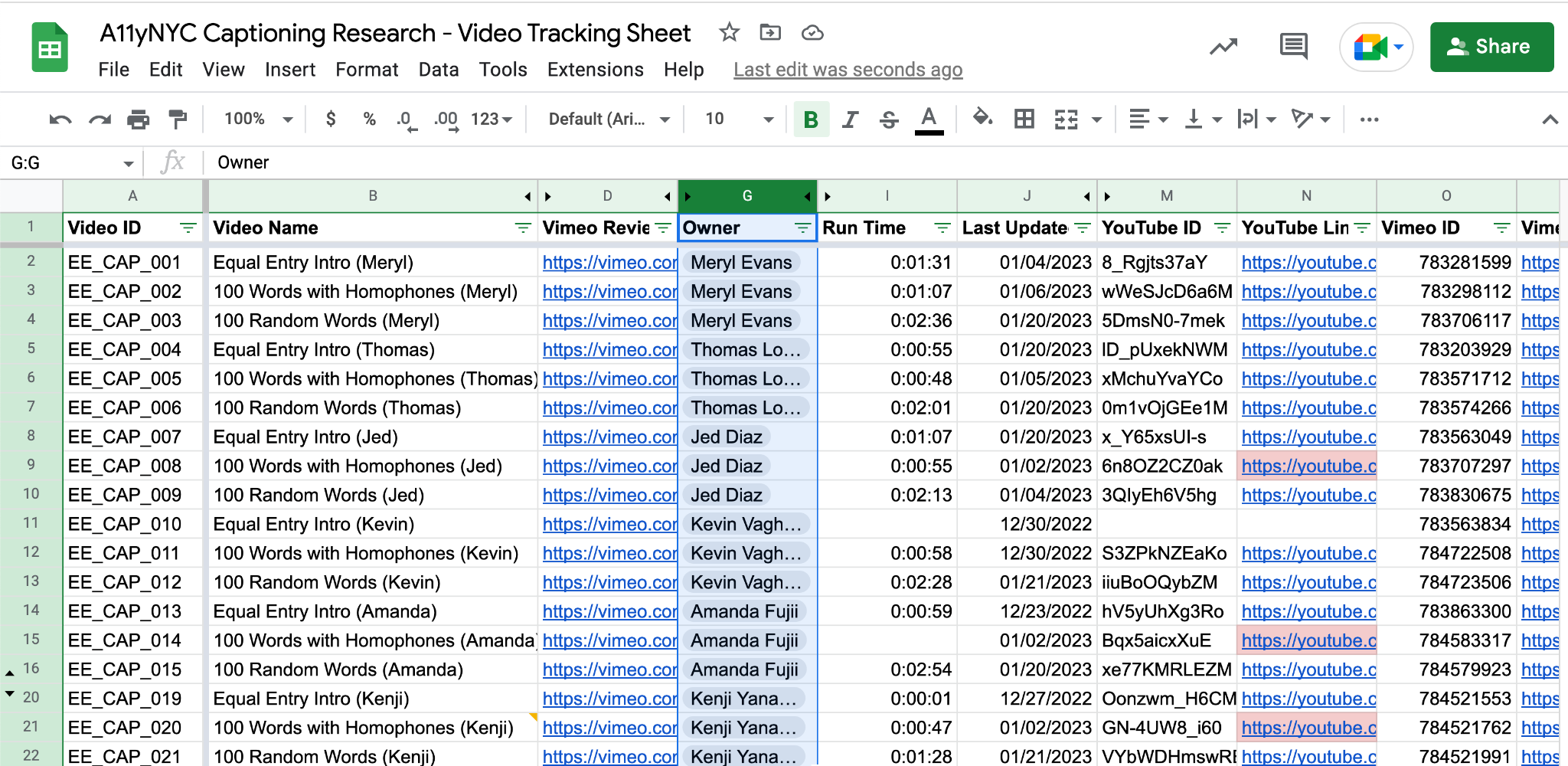
We created three test cases with six people doing each one for a total of 18 videos. Kevin created a Chrome plugin to automate the uploading process. Our thinking is that professionals want to scale the automatic captioning process as they have hours and hours of videos. The idea is that people will use APIs and automation to scale the process of adding accurate automatic captions to videos. That’s the dream.
The team wants to find a way to compare the captions or look for problems inside the files. The spreadsheet allows us to pick any file and do a comparison of the captions between the Gold and the AI. Gold captions are based on the script we wrote. We pull up the Gold captions and one of the AI services like Azure. It highlights the similarities and differences. We created three scripts, each containing 100 words. We wanted to have one variable that was the same for all of them.
Test Case No. 1: Equal Entry Intro
Our first test case was doing an introduction to our company, Equal Entry. This test focuses on proper nouns and acronyms. AI systems tend not to do these well because they don’t know what is important to someone. “Equal Entry” is important to our team but not to the general public. Words like “macOS” and “iOS” have specific ways to be identified.
AI systems won’t be familiar with niche terms and phrases like VPAT, which is Voluntary Product Accessibility Template. That’s a known term in accessibility, but not so much for outsiders. This test case also includes W3C, WCAG, A11yNYC, and A11yTokyo along with less commonly used words.
I shared a few screenshots from my intro video. Here are the accurate lines and what YouTube’s automatic captions showed.
Correct line
macOS, Windows, iOS, and Android.
We produce accessibility conformance
Captions
Mac OS Windows IOS and Android
we produce adaptability confirming
YouTube’s captions rarely contain punctuation and capitalization except for the occasional proper nouns as these captions show. However, it did not format Apple’s operating systems correctly.
Correct line
We improve access to technology
for people with disabilities
Captions
we improved actor to technology the
people with disabilities through
Just changing one word from present to past tense and using the incorrect word makes it hard to understand what the captions say.
Correct line
W3C work tag the death criteria?
W3C WCAG success criteria …
Captions
that will include our findings related to
the w3c work tag the death criteria
AI did not properly capitalize W3C and turned “wuh-cag” into “work tag” and “success criteria” into “death criteria.” Although the latter seems accurate as WCAG is notorious for being hard to understand.
How did the AI do with “A11y” as in “A11yNYC,” A11yVR,” and “A11yTokyo”? It did not get one right in any of the test cases. We tried ally (rhymes with apply), alley (as in bowling alley), and A-eleven-Y. The only way it’d get it right is if someone said the full name as in “Accessibility New York City.”
Test Case No. 2: 100 Random Words
The next test case was 100 random words. And we did this test case to determine if AI looks at the context of how the words are used. The purpose of this is to confuse the AI in the sense that there is no context. The following are the 100 random words we used and worked to avoid those with sound-alike words.
land, party, psychedelic, store, orange, terrify, love, redundant, far, few, rule, detail, disagree, card, strengthen, remain, form, obtain, needle, serve, outrageous, trousers, purple, fine, massive, sticker, tramp, mass, test, reflect, last, desk, snobbish, believe, raspy, top, impress, candle, miniature, insect, doctor, unadvised, cry, ship, uptight, puppy, weekend, plot, windy, blink, club, relax, wing, mask.
Here are some of the words and what AI thought the speaker said.
| Correct word | Automatic captions |
| abhorrent | a point |
| abhorrent | adherent |
| abhorrent | uphorrent |
| chivalrous | shiver |
| chivalrous | she wellness |
| lowly | nothing |
| lowly | slowly |
| lowly | lonely |
| lowly | lovely |
| stir | star |
| stir | steer |
| stir | still |
The following comes from my own 100 random words test. The script is the correct word. Then, the other three columns are the three different AIs.
| Script | YouTube | Vimeo | Azure |
| psychedelic | psychedelic | back a delic | that Cadillac |
| disagree | disagree | there’s a green | with a green |
| snobbish | cannabis | nabis | |
| uppity | I | A body | apparently |
How did Vimeo get “cannabis” from “snobbish” and Azure somehow shortened “cannabis” to “nabis”? I joked that YouTube was exposed to cannabis and forgot to caption “snobbish.”
From what the results show, it looks like there’s a little context that goes into the AI. But it’s not necessarily looking at the full sentence structure. Our hypothesis is that it may be looking at the previous and next words. As the 100 random words test shows, the AI performed worse because it had no hints to help it along.
Test Case No. 3: Homophones
Homophones are when two words have the same pronunciation, but different meanings or spelling. Here’s an example: their, there, and they’re. The point of testing homophones is to see if the AI considers context when determining what word to use.
The following video shows four versions of the same video with me. The upper left contains the script, which contains accurate captions. Below that is Whisper. The upper-right uses Azure’s AI, and below that is YouTube’s automatic captions.
Be aware that some people told me these videos are too much. You might consider moving the video player slider to jump around scenes. Then you can compare the captions without playing the video.
As for the results, the most accurate captions came from Whisper followed by Azure. YouTube doesn’t deserve to place due to its roll-up (moving or scrolling) captions, noticeable delay, and lack of capitalization and punctuation.
Recommendations
Companies taking a progress-over-perfection approach to captions would start by adding captions if they’re not already. There are companies that aren’t using automatic captions on social media platforms. Hence, adding captions is the first step. The next step is to edit the automatic captions. Make reviewing and editing automatic captions part of your video workflow.
One thing AI doesn’t do well is line length and line division. Line length is the length of each caption line. Line division is where the captions end on each line. Some refer to this as line breaks.
This video shows two side-by-side videos. The captions on both sides are accurate. The difference is that the left one follows line length and line division best practices. The right side shows how AI does line length and line division.
In short, AI doesn’t pay attention to line length and division. Following line length and division best practices make a big difference to the viewing experience. It reduces cognitive overload. Captioning Key has an excellent guide on line division.
In our work, we use a lot of the same words, acronyms, and phrases. These include W3C WCAG, a11y, NVDA, JAWS, operating systems, VPAT, and accessibility conformance reports to name a few. There are transcription services like Descript and Otter.ai that allow you to add custom vocabulary. The capability exists.
Currently, none of the AIs in the test cases allow users to add custom words. If these services want to make progress in improving automatic captioning, then they’ll let users create accounts to add custom vocabulary.
Any time you don’t see captions or edited automatic captions, contact the company and ask for them. Some companies have come through.
YouTube captions need the most help. So, contact the Google Accessibility Team about YouTube captions. Google owns YouTube. Ask them to please use punctuation and capitalization. One other thing to mention is to use pop-in captions instead of roll-up in a recorded video. The other AIs don’t do roll-up, so it’s doable.
Learn from Netflix
It’s possible to turn things around with accessibility and captions. In the past, Netflix got sued for lack of captioning. Now, they’re a leader. Netflix has high standards for subtitles and closed captions for all of its content.
“This is because at Netflix, Subtitles and Closed Captions are Primary Assets,” Netflix writes. “Subtitles and closed captions have historically been deemed a secondary asset. Even our own technical specification lists subtitles and closed captions (timed text) among several types of secondary assets that NETFLIX requires. The reality is that for millions of our members around the world, timed text files are primary assets.”
Netflix has a quality control process, even for subtitles in a different language. The little things in the translation are critical. They give an example of subtitles showing “Let me refresh your mind” instead of “Let me refresh your memory.” Little things like using the wrong word can disrupt a person’s viewing experience.
They’ll have someone who doesn’t know the language of the program watch a few minutes of content. If they come across anything that doesn’t read well, Netflix rejects the file. They expect companies to check things like this before sending the asset to Netflix. The company also pays attention to readability and speed.
The takeaway is to randomly select two to three minutes to watch to check the quality of the captions or subtitles. If it doesn’t pass, then send it back to the partner. After the partner resubmits the file, then check a different two to three minutes. It’s a more practical way of spot-checking the quality.
Do you care? For captions to improve, everyone needs to make their voice heard and send feedback. Advocate and push for changes.
Watch the Presentation
- Why quality captions matter
- AI captioning services used in test cases
- Test cases and results
- Recommendations
- Q&A with Thomas Logan and Meryl Evans
Calls to Action
- Make progress in creating high-quality captions.
- Including adding, reviewing, and editing automatic captions into your video creation workflow.
- Did you spot a video without captions? Ask for captions.
- Contact AI captioning services about:
- Caption length
- Line division
- Ability to add custom vocabulary
- Contact Google Accessibility: (Fill free to copy and paste the following.) “YouTube automatic captions rarely contain punctuation, sentences, and capitalization at the start of sentences. It makes the captions harder to read and understand. Please add this functionality.”
Resources
- Caption Guide
- Captioned side-by-side videos showing captioning best practices
- Captioning video FAQs
- Captioning Key Guide from DCMP
- Captions: Humans vs. Artificial Intelligence
- Gallaudet research [pdf] shows captions with punctuation lead to a better experience than without them
- Why are Netflix’s Standards for Subtitles and Captions So High?
- Video: Homophones comparison of AI captions (Four videos of Meryl)
- Video: Line length and line division comparison (Two videos of Meryl)
- W3C WAI Captions / Subtitles page
- WebVTT experiments
- Whisper AI transcription and translation page: Here’s how to create a caption file using Whisper.
- Choose “medium”
- Upload video or enter URL of video
- Select “transcript” or “translate” under “Task”
- Select “Submit”
Speaker bios
Thomas Logan is the founder and CEO of Equal Entry, co-founder of A11yNYC and A11yTokyo, and founder of Accessibility Virtual Reality (A11yVR). Connect with Thomas on LinkedIn.
Meryl Evans is an accessibility consultant with Equal Entry, co-organizer of A11yNYC and A11yVR, TEDx speaker, and a LinkedIn Top Voice. Connect with Meryl on LinkedIn and watch her TEDx Talk.
Want to work with us or start a conversation? Contact us.
The organisations that produce more videos than probably any other are colleges and universities. They typically produce 20 to 50,000 hours of videos, mostly lecture videos, annually. The temptation is to employ people to correct the captions, but that is hugely expensive.
The cheapest way to do it is for the speaker or lecturer to edit their own video, immediately afterwards while it is still fresh in their minds. They know what they said, and know the spellings of all the technical terms they used. So they can simply edit the .srt captions text file directly in a text editor, in a fraction of the time it would take anyone else to run the entire video, comparing the captions back to the audio, and making corrections, probably without expert knowledge of the subject.
Guy, yes! I often edit the SRT file because it’s much faster. The downside is that it won’t fix the line lengths as that requires fixing the timings and doing it in the SRT file isn’t effective. But it’s a good compromise to at least get edited captions.